Git 拾遗
-
.git文件目录 - commit,tree,block关系
- 分离头指针情况的注意事项(没有与branch进行关联)
- 修改commit的message
- rebase操作
- diff操作
- 恢复工作区,恢复索引区
- 删除,重命名文件
- ignore文件
.git文件目录
➜ .git git:(V.12.0) ls -l
total 1440
-rw-r--r-- 1 raojunbo staff 26 12 15 15:40 COMMIT_EDITMSG
-rw-r--r-- 1 raojunbo staff 1573 12 18 19:12 FETCH_HEAD
-rw-r--r-- 1 raojunbo staff 23 12 18 19:12 HEAD
-rw-r--r-- 1 raojunbo staff 41 12 18 19:12 ORIG_HEAD
-rw-r--r-- 1 raojunbo staff 551 12 12 12:56 config
-rw-r--r-- 1 raojunbo staff 73 11 30 11:39 description
-rw-r--r-- 1 raojunbo staff 311844 12 20 22:54 gitk.cache
drwxr-xr-x 13 raojunbo staff 416 11 30 11:39 hooks
-rw-r--r-- 1 raojunbo staff 391258 12 20 22:48 index
drwxr-xr-x 3 raojunbo staff 96 11 30 11:39 info
drwxr-xr-x 4 raojunbo staff 128 11 30 11:42 logs
drwxr-xr-x 256 raojunbo staff 8192 12 14 14:58 objects
-rw-r--r-- 1 raojunbo staff 1536 11 30 11:42 packed-refs
drwxr-xr-x 5 raojunbo staff 160 11 30 11:42 refs
HEAD 文件
存有当前分支的头指针。在切换分支的时候,会跟随分支的变化而变化。当然也可以不与分支挂钩,直接指向一个处理分支状态(任意指向的)也可以。config 文件
git config -l命令的内容
ORIG_HEAD 文件
FETCH_HEAD 文件
object目录
对象集,block ,commit,tree,tags;refs
git内部的命令
查看hash所代表的对象类型 `git cat-file -t 005642f3c41eecb8c56b8b77c4f100f1575ccf54查看hash所代表的对象实际内容
git cat-file -p 005642f3c41eecb8c56b8b77c4f100f1575ccf54
commit,tree,block关系
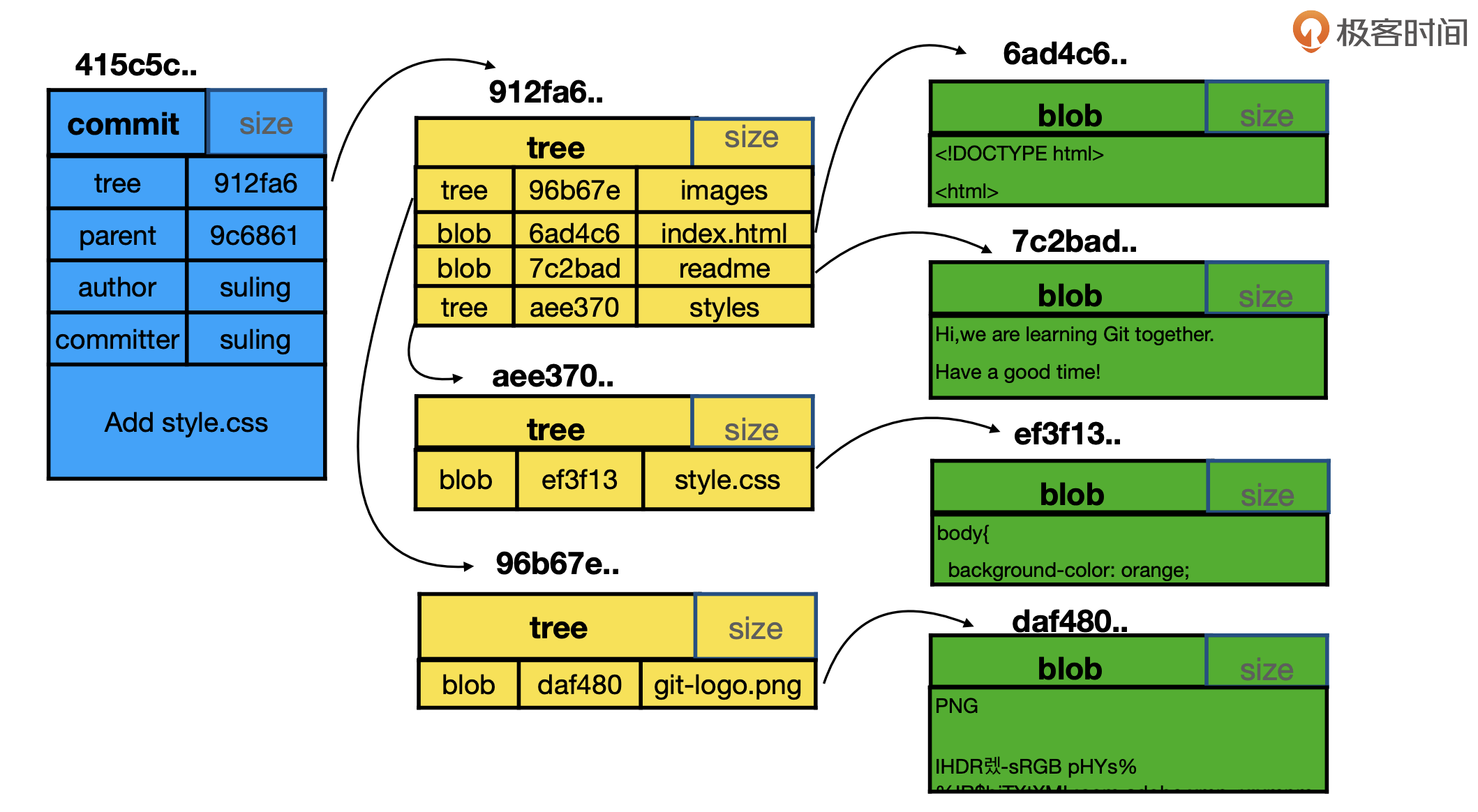
blob实际就是真实的文件
tree实际就是目录
commit是git里的东西是一个包含“根tree”的东西。commit里有parent(父commit),author(作者),committer(提交者)
分离头指针情况的注意事项(没有与branch进行关联)
➜ GitTestDir git:(master) git checkout 552aa3eba30936d5c4ecf148b38d0cbc89221fbc
Note: checking out '552aa3eba30936d5c4ecf148b38d0cbc89221fbc'.
You are in 'detached HEAD' state. You can look around, make experimental
changes and commit them, and you can discard any commits you make in this
state without impacting any branches by performing another checkout.
If you want to create a new branch to retain commits you create, you may
do so (now or later) by using -b with the checkout command again. Example:
git checkout -b <new-branch-name>
HEAD is now at 552aa3e add sty
➜ GitTestDir git:(552aa3e)
直接切换到一个指定的commit号,直接进入工作后,进行提交,如果在checkout 到其它分支,就会出现分离头指针,也就是没有基于某个分支。在后期,分支的指针会自动被清理掉。
git diff HEAD HEAD^ //head与父亲进行对比
git diff HEAD HEAD^ //head 与父亲的父亲进行对比
git diff HEAD HEAD~1 //head 与父亲进行对比
修改commit的message
对最近一次的message做修改
git commit --amend
rebase操作
修改以往的任何一个commit的message(rebase)
示例
commit3
commit2
commit1
我现在要,修改commit2,那么我就是git rebase -i commit1;以commit1作为基准,去修改其后面的commit信息。
rebase 命令的交互命令里有拿出commit,重新设置messge等操作。
修改后commit的commit号会发生变化。
合并以往的连续的几个commit(rebase)
示例
commit4
commit3
commit2
commit1
合并commit2,与commit3为commit5;这样就会形成一个新的commit;
合并以往的不连续的commit(rebase)
其实与前面一样,只是,列出commit ,然后描述命令
diff操作
比较工作区,索引区,HEAD的差异
git diff --cached比较索引区域HEAD的差别比较
git diff工作区与索引区的差别比较不同分支的同一个文件的差异
git diff temp master -- filename
temp是一个分支或者commitid,master是一个分支或者commitid;
恢复工作区,恢复索引区
- 清空工作区
git checkout file
git checkout .
- 将加入索引的放入工作区
git reset HEAD
- 清除最近的几个commit
git reset --hard commitid
删除,重命名文件
- 重命名文件
git mv filename1 filename2
- 删除文件
git rm filename
ignore文件
.gitignore告诉哪些不需要加入git的管理里
C语言拾遗
一:编译
不同的CPU制造商使用的指令系统和编码格式不同。例如Intel Corei7与ARM采用的就是不同的指令集。在编译时,编译器就需要将C语言编译成相应CPU的机器码。
补充说明:汇编语言是为特殊的CPU设计的一系列内部指令,是用助记符号表示,不同的CPU使用不同的汇编指令,就像C语言编译器编译成机器指令
C语言标准定义,C89,C99,C11(2011)等标准,而这种标准实际上是一种抽象。具体的实现是由相应的编译器解释。
编译流程,把源代码文件转换为可执行文件,具体是首先把源代码转换成中间代码(这个中间代码是没有连接其他模块的代码,因为这个中间代码可能用到了其他模块的函数,这个模块可以是其他模块也可是标准库),连接器把中间代码和其他代码合并(这个合并的过程就是连接的过程,是模块之间能正常找到调用),最终生成可执行文件。
GNU编译合集,LLVM项目分别是连个开源编译合集。都支持C的编译,在苹果系统目前采用LLVM项目里的Clang来编译C程序。
哈哈,从上述的整理,终于理解了Xcode里的Architectures(CPU架构),FrameSearchPath,Header SearchPath,Library SearchPath,Apple Clang的编译选项设置。
makefile的编译
在编译一个开源的C库时,比如Objectc的runtime,编译FFmpeg的库时,都会用到makefile文件来进行构建。
make通常被视为一种软件构建工具,是一个命令行工具。该工具主要经由读取一种名为“makefile”或“Makefile”的文件来实现软件的自动化建构程序。makeFile有其自己的语法。
- 文件包含
include
预处理
#define PI 3.13444
//带固定参数个数的宏
#define Men(X,Y) ((X)+(Y))
//可变参数个数的宏
#define PR(...) printf(__VA_ARGS__) //可变参数的宏
PR("Howdy");
PR("weight=%d, shipping=%d",wt,sp);
//文件包含
#include
当预处理器发现#include指令时,会替换源文件中的include指令。
(相当于把被包含的文件的全部内容输入到源文件#include指令所在的位置)
要深度的理解这句话的含义,包含,就是将代码实现替换到这。
头文件提供函数声明或者原型,库选项(也就是真正的库)告诉系统到哪里查找函数代码,或者是到源文件里查找代码。
- 区分宏定义的函数与函数区别
宏每调用一次,都会展开一次,是一种内联。而函数的调用。是会在一段函数指令里执行一次又一次。
条件编译
#define
#ifdef
#else
#endif
#ifndef
#if
#elif
预定义宏
C标准规定了一些预定义宏
__LINE__
__FILE__
__func__
完整项目多文件编译
二:指针的概念
从核心的去理解指针,就是一个地址值,一个变量的地址值。一个数组的首原始地址值。一个函数代码段的开始地址值。
指针的操作,是根据他们指向的数据的所占空间的大小来操作的。指向整数时,p+1,就是指向下一个整数。
int *p1 //指向int的指针变量(理解成一个整形变量的地址)
double *p2;
- 指针的应用
有时候,在函数外有个数组,想通过,这个函数修改数组里的值,要将整个修改逻辑放在这里。就需要传地址。(但外面是一个结构体时,有时遇到需要通过一个函数修改这个结构体的值,也会采用传地址的方式)。这是一个非常典型的应用场景。
//在采用传地址时,不允许修改这个数组的内容的值时,可以添加const。
//const修饰指针时,表示内容不允许修改
int sum (const int ar[],int n);
int sum (const int ar[],int n) {
int i;
int total = 0;
for (int = 0;i<n;i++){
total =+=ar[i];
}
return total;
}
- const修饰的区别的理解
const double *pd1;
double *const pd2;
要区分这两个含义,要从本质上理解,pd1的const修饰的是double *pd1,也就是这个指针变量,这个整体是值。也就是值是常量。
而,pd2的const修饰的pd2这个地址。是这个指针。也就是指针是常量
int val = 10;
const double *pd1 = &val;
*pd1 = 20;//不允许(因为修改了指针所指向内容的值)
double rate[] = {10,20,30};
double *const pc = rate;
pc = &rate[2];//不允许(因为是修改了指针的值)
哈哈,终于里理解了这个东西。
指针与object的关系
指针与NSObject的关系,要从C的内存管理角度去思考。
指针与数组的关
指针指向的就是数组的首地址。
指针与函数
指向函数的指针中存储着函数代码的起始地址。
void func (char *);
void (*pf) (cahr *);
pf 即是指向函数的指针
void ToUpper(char *);
void ToLower(char *);
pf = ToUpper;//将函数地址赋值给函数指针
pf = ToLower;//将函数地址赋值给函数指针
(*pf)("nihao");//调用函数
三:C中的字符串
- 字符串常量
这个字符串在编译的时候就已经确定。所以是在静态存储区。
char *str = "nihao";
//实际上"nihao"是一个字符数组。一个在末尾加了\0元素的字符数组。
- 数组形式与指针形式的不同
字符串常量是在编译时就确定好的在静态存储区。
const char ar[] = "something1";
const char *p = "something2";
对比说明:
"something1"是一个字符串常量,在给ar[]赋值时会将其拷贝到这个数组里。
"something2"是一个字符串常量,在静态存储区,在给*p赋值时,直接将静态区字符串的地址值给它。因为它是一个常量,内容没法修改,所以通常在前面加一个const;
四:C的内存管理
三个维度描述变量
链接
作用域
存储区
链接,作用域描述变量的可见性
存储区,描述变量的存储位置
- 外部变量
(在一个源文件里,在所有函数之外的变量),作用域是本文件,存储是静态存储,链接默认是外部链接,如果用static修饰,就是内部链接。
局部变量
在块,函数里的是局部变量,作用域是块或者函数内,存储默认是栈上,链接是内部链接。但若用static修饰,就是存储在静态区。
extern 申明这个源文件使用了外部变量。(哈哈,这里才是extern的本质)
动态内存分配
思考:为什么会有动态内存分配?
在我们的编译,执行时,根据已经制定好的内存管理规则,将自动选择作用域与存储区,自己管理内存(静态数据编译时分配,自动数据在执行时分配)。但,我们也可以程序员自己申请内存,自己释放内存,就是动态内存的分配。
五:结构体
结构体在实际的应用中相当重要。一些重要的库的数据描述都是用结构体表示。与结构体指针一同构建起一个大的程序库。比如objc-runtime,ffmpeg库。
struct book {
char title[10];
char author[20];
float value;
} abook;
book 是类型,abook是变量名
将结构体类型当做普通的变量类型就可以了。
struct book aBook; //结构变量
struct book *b; //指向结构的指针
aBook.value;//取值
b->value;//取值
- 结构体了字符数组与字符指针表示的区别
struct names{
char first[10];
char last[10];
}
struct pnames {
char *first;
char *last;
}
names占用20字节,pnames占用16字节。
names的本身存储位置是在它自己申请的位置。
pnames的first,last存存储在别处。用的时候要特别小心。
示例结构体内部字符指针表示的用法。(很重要)
下面是将结构体力的变量设置成字符指针。因为没有地方存储实际的值,所以需要用动态创建内存。
struct namect {
char *fname;
char *lname;
}
void getinfo(struct namect *pst){
char temp[20];
scanf("%s",tmp);//将输入的暂时存入tmp
pst->fanme= (char *)malloc(strlen(temp)+1);//动态创建一个空间
strcpy(pst->fname,temp);//将tmp的拷贝到动态空间
}
六:抽象数据接口
链表
队列
结语:至此关于C的一些核心概念就都搞清楚了。
七:示例
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#define SLENGTH 80
struct namect {
char *fname;
char *lname;
int letters;
};
typedef struct namect NAMEct;
//以下都是函数声明
//将结构体指针作为参数传递
void getinfo (struct namect *);
void makeinfo (struct namect *);
void showinfo (const struct namect *);
void cleanup (struct namect *);
char * s_gets(char *st ,int n);
int main () {
NAMEct person;
getinfo(&person);
makeinfo(&person);
showinfo(&person);//显示信息
cleanup(&person);//调用该函数时释放内存
}
void getinfo (struct namect *pst){
char temp[] = "naihao";
char temp2[] = "naihao2";
pst->fname = (char *) malloc(strlen(temp) +1);//申请内存
strcpy(pst->fname,temp);//将字符拷贝到生成的内存中
pst->lname = (char *) malloc(strlen(temp2) +1);//申请内存
strcpy(pst->lname,temp2);
}
void makeinfo (struct namect *pst){
pst->letters = strlen(pst->fname) + strlen(pst->lname);
}
void showinfo(const struct namect *pst){
printf("firstName:%s secondName:%s letters:%d",pst->fname,pst->lname,pst->letters);
}
void cleanup (struct namect *pst){
free(pst->fname);//释放内存
free(pst->lname);//释放内存
}
Copyright © 2015 Powered by MWeb, Theme used GitHub CSS.