GCD
本篇内容
1. 死锁
2. 异步与同步概念
3. 串行与并发概念(重点)
4. dispatch_group
5. dispatch_barrier_async
6. 信号量
6. dispatch_source(重点)
简介
在单核的CPU里,采用分时的执行,来回在不同线程之间进行切换。在多核的CPU里可以同时多个线程,也可以切换线程。这样就实现多线程。
多线程带来的问题
数据竞争:多个线程更新相同的资源
死锁:线程之间相互等待
消耗大量内存:太多线程会消耗大量内存
死锁
在GCD中,以同步分发的方式非常容易出现死锁。死锁的本质资源的相互等待。异步调用不会产生死锁。
dispatch_queue_t queueA;
dispatch_sync(queueA, ^{
dispatch_sync(queueA, ^{
[self foo];
});
});
/*
一旦进入第二个dispatch_sync就会死锁
它们两个在同一个线程里执行外面的正在执行,第二个会等待外面的执行完,而第二个永远都不会执行完。
*/
队列
同步队列只是在执行任务时,顺序的从对列里去任务。在一个任务没有完时不会执行下一个任务。
并发队列是执行任务时,在一个任务没有执行完,可以去拿另一个任务去找线程执行。
异步
异步操作有开启线程的权利。
同步操作没有开启线程的权利。
不同执行方式在不同的队列里执行
同步异步在并发串行队列里的四种组合
同步与异步决定是否开启线程
串行与并发决定拿任务方式
任务时需要线程去执行的。也就时需要考虑,有线程没任务,有任务没线程去执行的情况。
- 同步执行 串行队列 因为是同步,不会从线程池里拿线程执行,会在当前线程里执行下一个任务(要在当前任务执行完后)。即若果在主线程里同步执行任务。会出现死锁。
/*
死锁
*/
dispatch_queue_t queue = dispatch_get_main_queue();
dispatch_sync(queue, ^{
NSLog(@"%@",[NSThread currentThread]);
});
- (void)gcdDemo1 {
//1.创建串行队列
dispatch_queue_t q = dispatch_queue_create("demo1_seral", DISPATCH_QUEUE_SERIAL);
//2.同步执行任务
for (int i =0; i< 20; i++) {
dispatch_sync(q, ^{
NSLog(@"demo1 %@",[NSThread currentThread]);
});
}
}
- 同步执行 并发队列 因为是同步,不会开启线程,因为是并发队列,拿任务可以并发,但没有线程执行,所有还是一个一个执行
//1.创建串行队列
dispatch_queue_t q = dispatch_queue_create("demo4_seral", DISPATCH_QUEUE_CONCURRENT);
//2.同步执行任务
for (int i =0; i< 20; i++) {
dispatch_sync(q, ^{
NSLog(@"demo3+%@, %@",@(i),[NSThread currentThread]);
});
}
NSLog(@"come here");
- 异步执行 串行队列 因为是异步,可以去线程池里拿线程执行。当前是串行队列,要等一个任务执行完后才去拿下一个任务。所以还是一个一个执行
- (void)gcdDemo2 {
//1.创建串行队列
dispatch_queue_t q = dispatch_queue_create("demo2_seral", DISPATCH_QUEUE_SERIAL);
//2.同步执行任务
for (int i =0; i< 20; i++) {
dispatch_async(q, ^{
NSLog(@"demo2+%@, %@",@(i),[NSThread currentThread]);
});
}
NSLog(@"come here");
}
- 异步执行 并发队列 因为是异步,可以去线程池中拿线程执行。当前是并发队列。当前任务没有执行完可以去拿下一个任务执行,因为是并发,可以从线程池里拿新的线程去执行这个任务。这时就真正实现了幷发执行。
- (void)gcdDemo3 {
//1.创建串行队列
dispatch_queue_t q = dispatch_queue_create("demo3_seral", DISPATCH_QUEUE_CONCURRENT);
//2.同步执行任务
for (int i =0; i< 20; i++) {
dispatch_async(q, ^{
NSLog(@"demo3+%@, %@",@(i),[NSThread currentThread]);
});
}
NSLog(@"come here");
}
- 应用(如果将这个例子理解了,就真正理解的同步异步执行与串行并发对列) 指定一个同步任务,让所有异步任务等待同步任务执行完后才执行。 解决方法: 在一个并发队列里先执行加入这个同步任务,在加入后面两个异步任务。因为是同步任务在前,不会有开启多余的线程去执行后面的任务。当第一个执行完,执行到第二个时候,是异步的,可以开启线程执行其他的,因为是并发队列,第三个任务有线程可以用来执行。
- (void)gcdDemo6 {
dispatch_queue_t loginQueue = dispatch_queue_create("rao-login-queue", DISPATCH_QUEUE_CONCURRENT);
void (^task)(void) = ^(){
dispatch_sync(loginQueue, ^{
NSLog(@"用户登录了%@",[NSThread currentThread]);
});
dispatch_async(loginQueue, ^{
NSLog(@"用户支付了%@",[NSThread currentThread]);
});
dispatch_async(loginQueue, ^{
NSLog(@"用户下载了%@",[NSThread currentThread]);
});
};
dispatch_async(loginQueue, task);
}
dispatch group
使用场景:在一个对列里并发执行完后,想执行一个操作,就可以用dispatch_group
dispatch_queue_t queue = dispatch_queue_create("rao-queue", DISPATCH_QUEUE_CONCURRENT);
dispatch_group_async(group, queue, ^{
NSLog(@"down load1%@",[NSThread currentThread]);
});
dispatch_group_async(group, queue, ^{
NSLog(@"down load2%@",[NSThread currentThread]);
});
dispatch_group_async(group, queue, ^{
NSLog(@"down load3%@",[NSThread currentThread]);
});
//当前面的所有
dispatch_group_notify(group, queue, ^{
NSLog(@"所有的都执行完%@",[NSThread currentThread]);
});
//在主队列里进行更新
dispatch_group_notify(group,dispatch_get_main_queue(), ^{
NSLog(@"所有的都执行完%@",[NSThread currentThread]);
});
dispatch_barrier_async
dispatch_barrier_async等待之前追加的任务执行完后,就会执行这个任务,并且不会执行下一个任务,要等这个任务执行完后,才会并发执行下一个任务。
- (void)viewDidLoad {
[super viewDidLoad];
dispatch_queue_t queue = dispatch_queue_create("label", DISPATCH_QUEUE_CONCURRENT);
static NSInteger readCount = 0;
void(^read)(void) = ^() {
NSLog(@"这是read%@",@(readCount));
};
void(^write)(void) = ^(){
readCount++;
NSLog(@"这是write%@",@(readCount));
};
dispatch_async(queue, read);
dispatch_async(queue, read);
dispatch_async(queue, read);
dispatch_async(queue, read);
dispatch_barrier_async(queue, write);
dispatch_async(queue, read);
dispatch_async(queue, read);
}
信号量
NSMutableArray是线程不安全的,当有多个线程同时对数组进行操作的时候可能导致崩溃或数据错误。这里采用的就时信号量,所谓信号量,可以理解成一个数,占有空间时+1,走开始-1;
- (void)viewDidLoad {
[super viewDidLoad];
//并发写入数据
dispatch_queue_t queue = dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_HIGH, 0);
dispatch_semaphore_t semaphore = dispatch_semaphore_create(1);//创建信号量
NSMutableArray *array = [[NSMutableArray alloc]init];
for (int i = 0 ; i<1000; i++) {
dispatch_async(queue, ^{
dispatch_semaphore_wait(semaphore, DISPATCH_TIME_FOREVER);//减少信号量
[array addObject:@(i)];
});
dispatch_semaphore_signal(semaphore);//提高信号量
}
锁
锁的部分参考深入理解iOS开发中的锁
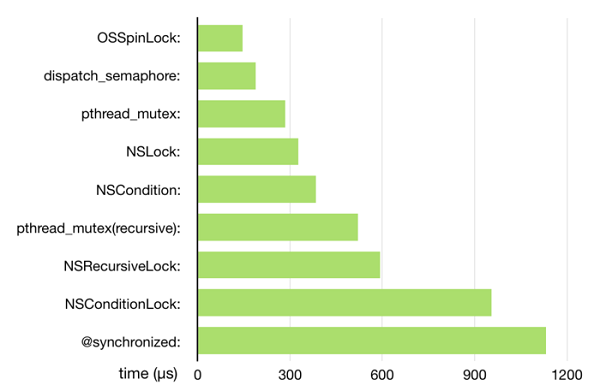
本图来自ibireme
- OSSpinLock
自旋锁的实现原理比较简单,就是死循环。当a线程获得锁以后,b线程想要获取锁就需要等待a线程释放锁。在没有获得锁的期间,b线程会一直处于忙等的状态。如果a线程在临界区的执行时间过长,则b线程会消耗大量的cpu时间,不太划算。所以,自旋锁用在临界区执行时间比较短的环境性能会很高。
dispatch_semaphore
dispatch_semaphore实现的原理和自旋锁有点不一样。首先会先将信号量减一,并判断是否大于等于0,如果是,则返回0,并继续执行后续代码,否则,使线程进入睡眠状态,让出cpu时间。直到信号量大于0或者超时,则线程会被重新唤醒执行后续操作。pthread_mutex
pthread_mutex表示互斥锁,和信号量的实现原理类似,也是阻塞线程并进入睡眠,需要进行上下文切换。NSLock
NSLock在内部封装了一个 pthread_mutex,属性为 PTHREAD_MUTEX_ERRORCHECK。NSCondition
NSCondition封装了一个互斥锁和条件变量。互斥锁保证线程安全,条件变量保证执行顺序。NSRecursiveLock
递归锁,pthread_mutex(recursive)的封装。@synchronized:
一个对象层面的锁,锁住了整个对象,底层使用了互斥递归锁来实现。
事件源
Runloop里我们说过source_t的概念,其实与队列的源是相同的。Runloop提供对源的监控。队列也可以实现对源的监控。且都可以创建自定义源。
理解:dispatch都是主动添加任务到队列中,然而当系统事件发生时,我们希望做一定的工作当监听到系统事件后就会触发一个任务,并自动将其加入队列执行,这里与之前手动添加任务的模式不同,一旦将Diaptach Source与Dispatch Queue关联后,只要监听到系统事件,Dispatch Source就会自动将任务(回调函数)添加到关联的队列中。(这个概念在监听系统事件时做一定的操作时是很有用处的!!!哈哈)
监听事件类型
Dispatch Source一共可以监听六类事件,分为11个类型,我们来看看都是什么:
DISPATCH_SOURCE_TYPE_DATA_ADD:属于自定义事件,可以通过dispatch_source_get_data函数获取事件变量数据,在我们自定义的方法中可以调用dispatch_source_merge_data函数向Dispatch Source设置数据,下文中会有详细的演示。
DISPATCH_SOURCE_TYPE_DATA_OR:属于自定义事件,用法同上面的类型一样。
DISPATCH_SOURCE_TYPE_MACH_SEND:Mach端口发送事件。
DISPATCH_SOURCE_TYPE_MACH_RECV:Mach端口接收事件。
DISPATCH_SOURCE_TYPE_PROC:与进程相关的事件。
DISPATCH_SOURCE_TYPE_READ:读文件事件。
DISPATCH_SOURCE_TYPE_WRITE:写文件事件。
DISPATCH_SOURCE_TYPE_VNODE:文件属性更改事件。
DISPATCH_SOURCE_TYPE_SIGNAL:接收信号事件。
DISPATCH_SOURCE_TYPE_TIMER:定时器事件。
DISPATCH_SOURCE_TYPE_MEMORYPRESSURE:内存压力事件。
- timer_source 示例
dispatch_queue_t queue = dispatch_queue_create("queue", DISPATCH_QUEUE_CONCURRENT);
dispatch_source_t timer = dispatch_source_create(DISPATCH_SOURCE_TYPE_TIMER, 0, 0,queue);
if(time){
dispatch_source_set_timer(timer, dispatch_walltime(NULL, 0), 1, 1);
dispatch_source_set_event_handler(timer, ^{
});
dispatch_resume(timer);
}
- 监听度文件读事件
dispatch_source_t processContentsOfFile(const char *fileName) {
//prepare the file for reading
int fd = open(fileName,O_RDONLY);
if(fd == -1){
return NULL;
}
fcntl(fd,F_SETFL,O_NONBLOCK);
dispatch_queue_t queue = dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0);
dispatch_source_t readSource = dispatch_source_create(DISPATCH_SOURCE_TYPE_READ, fd, 0, queue);
if(!readSource){
close(fd);
return NULL;
}
dispatch_source_set_event_handler(readSource, ^{
});
return nil;
}
取消dispatch_source
当设置了Dispatch source对象将一直保持有效状态,除非手动调用dispatch_source_cancel函数来取消它。但取消了dispatch source对象后,将不能再接收到新的事件
暂停与恢复dispatch_source
可以通过使用dispatch_suspend和 dispatch_resume函数来暂停和恢复事件传递给dispatch source对象
iOS如何将像素显示到屏幕
绘制像素到屏幕
参考文章绘制像素到屏幕
参考文章iOS视图,动画渲染机制
本文将总结
1. 位图数据如何存储的?
2. 像素绘制到屏幕上需要经历的流程?
3. CPU的工作是什么?
4. GPU的工作是什么?
5. 离屏渲染的取舍?
6. 绘制与动画的关系?
7. 渲染性能优化的总结
一.像素
显示在屏幕上的是什么?
当像素映射到屏幕的时候,每一个像素均由三个颜色组件构成:红,绿,蓝,透明度。三个独立的颜色单元会根据给定的颜色显示到一个像素上。例如在iPhone5的显示屏上是1136 *640个像素。
1.1 像素在内存里的默认布局
A R G B A R G B A R G B
| pixel 0 | pixel 1 | pixel 2
0 1 2 3 4 5 6 7 8 9 10 11 ...
1.2 二维数据
在实际使用像素数据时,有时会使用二位数据。就时颜色组件红,绿,蓝,alpha,每一个组件是一个数组。这样可以实现很好的对数据进行压缩或者其他处理。
二. 软件构成
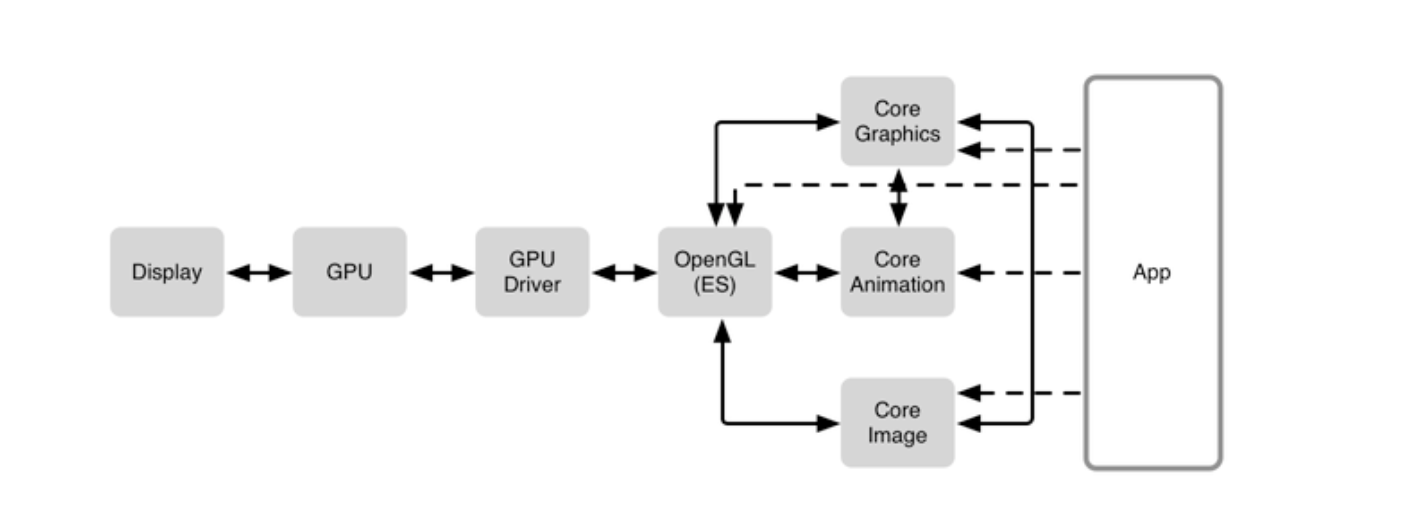
Display(显示屏)
GPU
GPU Driver
OpenGL
CoreGraphics
CoreAnimation
CoreImage
GPU是一个专门为图形并发计算而量身定做的处理单元。
CoreAnimation使用CoreGraphics来做渲染。CoreGraphics在CPU里进行运算出数据,形成位图包装成纹理交给OpenGl进行操作GPU进行渲染。
2.1 工作大致流程
GPU需要将每一个frame的纹理合成在一起。每一个纹理会占用VRAM,
CPU开始程序时,会让CPU从bundle加载一张PNG的图片并且解压它,这所有的事情都在CPU上。在显示文本时,会促进CoreText和CoreGrapic生成一个位图(coreText排版器最终也是要绘制到图片上下文),一旦准备好,它将会被作为一个纹理上传到GPU并显示出来。但滚动或者在屏幕上移动文本时,不管怎样,同样的纹理会能够复用,CPU只需要简单告诉GPU新的位置就可以,所有GPU可以重用存在的纹理,CPU并不需要重新渲染文本,并且位图也不需要重新上传到GPU。
三. 纹理合成
在简化的理解中,纹理相当于CoreAnimatio里的CALayer,纹理可以有位图内容,其实CALayer也是有位图内容的,对于每一个纹理,所有的纹理都以某种方式叠加在彼此的顶部。当两个纹理覆盖在一起时候,GPU要为所有像素做合成操作。
不透明的合成
在不透明时,即opaque=yes时,不用合成,直接取上面的纹理。这样就减少了合成的时间。(这也就是为什么在做性能优化时,减少层次关系,减少不必要的透明)mask合成
一个图层可以有一个和它相关联的 mask(蒙板),mask 是一个拥有 alpha 值的位图,当像素要和它下面包含的像素合并之前都会把 mask 应用到图层的像素上去。当你要设置一个图层的圆角半径时,你可以有效的在图层上面设置一个 mask。但是也可以指定任意一个蒙板。比如,一个字母 A 形状的 mask。最终只有在 mask 中显示出来的(即图层中的部分)才会被渲染出来。
所谓的mask就是一mask的不透明区域,显示本身的内容。实际上mask也是一种合成。
3.1 离屏渲染
帧缓冲区
屏幕缓存区,在屏幕上屏幕外缓冲区
屏幕外缓冲区哪些情况会默认会强制进行离屏渲染?
CoreAnimation为了应用mask会强制进行屏幕外渲染。
CoreAnimation设置圆角半径会进行屏幕外渲染
CoreAnimation设置阴影也会出现屏幕外渲染
设置层为光栅化layer.shouldRasterize = yes
(特别说明下,rasterize是图层的光栅化,会造成离屏渲染)离屏渲染的性能取舍?
一般情况下需要避免离屏渲染,因为这是很大的消耗。直接将图层合成到帧的缓冲区(屏幕上)比先创建屏幕外缓冲区,然后将屏幕外缓冲区内容般到帧缓冲区要廉价很多。但有时候需要渲染树很复杂,可以强制离屏渲染那些图层,这样就可以缓存合成的结果。性能就会有所提升。(当使用离屏渲染时,GPU第一次会混合所有图层到一个基于新的纹理的位图缓存上,然后使用这个纹理来绘制到屏幕上)。当对这个纹理进行移动,变形等操作时,可以使用这个位图缓存。这样这部分的合成将减少很多工作。其实这就是做动画的流畅的原因。所以要不要离屏渲染,要看有取舍,一般对于静态的不经常变更的可以使用离屏,增加缓存。对于经常变更的就最好不要使用离屏。这样会增加建立屏幕外缓冲区的时间,以及屏幕内与屏幕外的切换时间。
3.2离屏渲染检测
Instrument的CoreAnimationg工具,Color Offscreen-Rendered Yellow,是检测离屏渲染。Color Hits Green and Misses Red 选项,绿色代表无论何时一个屏幕外缓冲区被复用,而红色代表当缓冲区被重新创建。
四. CoreAnimation与CoreGraphics与OpenGLES
CoreAnimation利用CoreGraphics绘制,CoreGraphics利用OpenGLES实现绘制。。
OpenGLES做的就是将纹理合并,做些另外的操作,比如mask,阴影等。OpenGLES对这些有层次关系的纹理进行合成,而这些具体的操作是通过GPU来实现的(也就是通过OpenGLES来操作GPU,OpenGLES只是编程接口)。
CoreAnimation重要的任务是判断出哪些图层需要被重新绘制,绘制完成后会有生成bitmap,CoreAnimion里的图层有backsore,就是一这个bitmap;这个bitmap可以是读取的图片数据,也可以是利用CoreGrapics绘制的。无论是给的图片还是自己通过CrorCrapics绘制的最终,提交把这个位图数据交个生成的纹理(这个纹理与这个Layer相对应)。
五. CPU瓶颈与GPU瓶颈优化
要在1/60里完成渲染工作,CPU与GPU的总时间不能操作这个时间。否则就会出现掉帧。
在出现性能瓶颈时, 我们采用Instrument里的,OpenGL ES Driver instrument 进行查看。
六. CoreGraphics
CPU实现的是位图绘制,这个绘制过程是用CoreGraphics完成的,也就是通过CPU进行计算而来。我们自己画的线条,长方形,通过CPU计算,最终将数据形成与CGContext里。
当渲染系统准备好,它会调用视图图层的-display方法.此时,图层会装配它的后备存储。然后建立一个 Core Graphics 上下文(CGContextRef),将后备存储对应内存中的数据恢复出来,绘图会进入对应的内存区域,并使用CGContextRef 绘制
UIKit 版本的代码为何不传入一个上下文参数到方法中?
这是因为当使用 UIKit 或者 AppKit 时,上下文是唯一的。UIkit 维护着一个上下文堆栈,UIKit 方法总是绘制到最顶层的上下文中。UIGraphicsGetCurrentContext() 来得到最顶层的上下文。你可以使用 UIGraphicsPushContext() 和 UIGraphicsPopContext() 在 UIKit 的堆栈中推进或取出上下文。自己创建一个位图上下文
自己创建的CGContext,那么绘制的数据在这个自己创建的CGContext里,可以用这个CGGcontext形成位图或者图片。(这里可以自己绘制然后生成图片,也可以实现异步绘制,哈哈)
6.1 drawRect原理
当你调用 -setNeedsDisplay,UIKit 将会在这个视图的图层上调用 -setNeedsDisplay。这为图层设置了一个标识,标记为 dirty,但还显示原来的内容。它实际上没做任何工作,所以多次调用 -setNeedsDisplay并不会造成性能损失。当渲染系统准备好,它会调用视图图层的-display方法.此时,图层会装配它的后备存储。然后建立一个 Core Graphics 上下文(CGContextRef),将后备存储对应内存中的数据恢复出来,绘图会进入对应的内存区域,并使用 CGContextRef 绘制。
当你使用 UIKit 的绘制方法,例如: UIRectFill() 或者 -[UIBezierPath fill] 代替你的 -drawRect: 方法,他们将会使用这个上下文。使用方法是,UIKit 将后备存储的 CGContextRef 推进他的 graphics context stack,也就是说,它会将那个上下文设置为当前的。因此 UIGraphicsGetCurrent() 将会返回那个对应的上下文。既然 UIKit 使用 UIGraphicsGetCurrent() 绘制方法,绘图将会进入到图层的后备存储。如果你想直接使用 Core Graphics 方法,你可以自己调用 UIGraphicsGetCurrent() 得到相同的上下文,并且将这个上下文传给 Core Graphics 方法。
总结下:检测是否需要重绘,需要重绘,若果实现了drawRect就会生成一个相应大小的后备存储。然后调用drawRect里的代码进行绘制。将数据写入上下文,幷形成新的后备存储。幷将新的后备存储交给GPU渲染。(这里如果不需要绘制,就不要重写drawRect方法了,这样就不会生成后没有必要的备存储对象了,以免造成性能的浪费),幷切每次出现重绘时,都会执行drawRect方法。造成时间和内存浪费。可以采用自己创建位图上下文,生成图片后,赋值给视图。这样可以避免不断绘制。
6.2 异步绘制
将一些耗时的工作,避过图片的获取,图片的解码等工作放到子线程中去做,形成图片后,在放到主线程里将图片放进去。
UIImageView *view; // assume we have this
NSOperationQueue *renderQueue; // assume we have this
CGSize size = view.bounds.size;
[renderQueue addOperationWithBlock:^(){
UIImage *image = [renderer renderInImageOfSize:size];
[[NSOperationQueue mainQueue] addOperationWithBlock:^(){
view.image = image;
}];
}];
6.3 图片解码
你需要知道在 GPU 内,一个 CALayer 在某种方式上和一个纹理类似。图层有一个后备存储,这便是被用来绘制到屏幕上的位图。
在给CALayer设置图片时,CoreAnimation会将其查看这个图片时否已经解码,没解码的化话进行解码(这里就是一个优化点,可以将解码的工作全部放到子线程里进行,哈哈)。
imageNamed:从 bundle 里加载会立马解压。一般的情况是在赋值给 UIImageView 的 image 或者 layer 的 contents 或者画到一个 core graphic context 里才会解压。
6.4 可变尺寸的图片
使用较小的图片好处
解码快
占用内存小
七. 完整的绘制与动画流程
动画在APP内部的4个阶段
布局:
在这个阶段,程序设置 View/Layer 的层级信息,设置 layer 的属性,如 frame,background color 等等。创建 backing image:在这个阶段程序会创建 layer 的 backing image,无论是通过 setContents 将一个 image 传給 layer,还是通过 drawRect:或 drawLayer:inContext:来画出来的。所以 drawRect:等函数是在这个阶段被调用的。
准备:在这个阶段,Core Animation 框架准备要渲染的 layer 的各种属性数据,以及要做的动画的参数,准备传递給 render server。同时在这个阶段也会解压要渲染的 image。(除了用 imageNamed:方法从 bundle 加载的 image 会立刻解压之外,其他的比如直接从硬盘读入,或者从网络上下载的 image 不会立刻解压,只有在真正要渲染的时候才会解压)。
提交:在这个阶段,Core Animation 打包 layer 的信息以及需要做的动画的参数,通过 IPC(inter-Process Communication)传递給 render server。
动画在APP外部的2个阶段
当这些数据到达 render server 后,会被反序列化成 render tree。然后 render server 会做下面的两件事:
根据 layer 的各种属性(如果是动画的,会计算动画 layer 的属性的中间值),用 OpenGL 准备渲染。
渲染这些可视的 layer 到屏幕。
如果做动画的话,最后的两个步骤会一直重复知道动画结束。
八. 渲染性能优化的总结
隐藏的绘制
UILabel将text画入backing image。也就是将文字搞成相对应的图片(文字最终都会是图片)。如果改了一个包含 text 的 view 的 frame 的话,text 会被重新绘制。Rasterize
当使用layer的shouldRasterize的时候,layer会被强制绘制到一个offscreen image上,并且会被缓存起来。这种方法可以在比较复杂的不会变化的图层上。离屏绘制
使用 Rounded corner, layer masks, drop shadows 的效果可以使用 stretchable images。比如实现 rounded corner,可以将一个圆形的图片赋值于 layer 的 content 的属性。并且设置好 contentsCenter 和 contentScale 属性。Blending
如果一个 layer 被另一个 layer 完全遮盖,GPU 会做优化不渲染被遮盖的 layer,但是计算一个 layer 是否被另一个 layer 完全遮盖是很耗 cpu 的。将几个半透明的 layer 的 color 融合在一起也是很消耗的。opaque
减少透明,减少合成时间drawRect
没有必要不要在drawRect里实现。可以采用异步绘制。图片解码
图片解码可以异步进行,不要在设置图片的时候解码
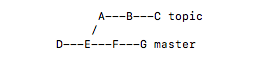
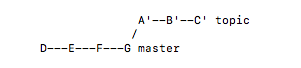
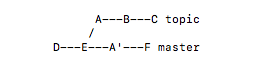
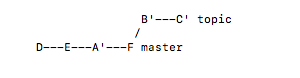



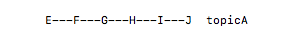

深入理解Git
本篇文章是对使用Git的使用的概述。然后对几个忽略的概念做了一下重新理解。
- 一:Git 文件管理
- 二:Git分支操作
- 三:Git提交操作
- 四:Git的Diff操作
- 五:远程版本库
- 六:多个仓库可以共用一个对象库吗?(很重要,初学时的疑惑点)
- 七:解释fast-forward,non-fast-forward
- 八:解释git rebase ,git cherry-pick
- 九:提交范围(很重要)
- 十:多人协作开发时,造成起点分叉的原因(还待研究)
一:Git 文件管理
工作目录
纯净的工作文件索引
git add命令,将对象添加到对象库中,维持一个新的目录树,这个目录树在工作区没有再次改变时是与工作区相同的目录树。新添加的修改与对象库里的目录树是不同的。而这些新添加的就是待提交到对象库里的修改。对象库
包括,提交对象(commit),目录树对象(tree),实际的数据(blob),标签(tag);
blob对应正真的数据,文件的每个一版本。
tree对应目录。树对象下可以有其他数,最终都会有blob的指向
commit对应提交。对应当前目录树的一个完整快照从总体上来理解,就是工作目录,索引,对象库,都有一个目录树。从编辑,git add ,git commit,的三个过程,就是目录树的同步工作。当然对象库里的commit是某个目录树的引用即快照。这就快照就是目录树,而这个目录树维持着blob的数据。而commit就记录着作者日志等信息。而commit实际上是链表,将一个个commit串联起来,构成一个分支开发线。
二:Git分支操作
远程追踪分支(追踪远程分支),本地追踪分支(追踪"远程追踪分支"),本地分支(谁也不追踪,自己玩,不具有pull功能)
分支管理
git show-branch
git branch -d "branchname"
git branch
git branch -r
git branch -a
git branch -d
git branch -D
git branch testbranch //从当前commit创建分支
git branch testbranch2 commitID //从指定的commit创建分支分支合并
HEAD 当前引用
FETCH_HEAD 远程跟踪分支的最新
ORIGIN_HEAD 本分支合并前的commit号或者是reset前的commit号
MERGE_HEAD 合并时别人的分支的commit号(在有冲突时,哈哈)
所有对对分支的操作都应该在本地操作。
三:Git提交操作
git reset git reset 精髓是--soft ,--mixed,--hard,三者对于head指向,索引树,工作目录的影响。
git reset --soft 提交会将HEAD引用指向给定提交,相当于是将后面对commit的提交的修改重新放入了索引里;(commit树与索引树不同)git reset --mixed 提交会将HEAD指向给定提交,索引内容改变以符合给定提交的树。相当于是将后这个提交的后面的带面放到工作区;(commit树与索引树相同,工作树不同)git reset --hard 提交会将HEAD指向给定提交。并且三个树同步。即此种情况,会导致新修改丢失。(工作区树,索引区,commit树)特别说明:
git reset --mixed,让你有机会重新编辑文件(系统默认)
git reset --soft,让你有机会重新修改提交日志
giet reset --hard,全部删除了.没机会了git revert
指定反转一个提交,并形成新的这个提交记录git cherry-pick(重点,难点)
将其他分支的commit指定合并到当前分支并形成一个新的提交git commit --amend
修改最新提交,主要是对此提交新添加内容,并在修改了最新的提交git checkout
检出分支内容,即沿着当前分支树路径取出内容git rebase(这个概念理解的不够透彻)
git rebase master topic
将topic可达到master的提交添加到master的最新的后面。(有时也有说成,将你的补丁变基到master分支的头)git rebase --onto master maint^ feature
将从maint到feature的路径的提交,迁移到master后面(onto表示把一条分支上的开发线整个移植到完全不同的分支上)。在此期间需要使用git rebase --continue 继续下一个提交,也可git rebase --abort进行编辑中止git rebase -i ( -- interactive)
合并提交,或者改变提交顺序,或者删除,编辑,即将两个提交合并成一个提交(注意不是合并分支),
特别注意:这些操作可以专门针对某个文件进行操作。直接在commit后面添加 文件名就可以了
四:Git的Diff操作
diff的操作在实际的工作中是很有用的。
git diff
显示工作目录和索引差异git diff commit
显示工作目录与commit差异git diff --cached commit
显示索引中的变更和给定提交中的变更差异git diff commit1 commit2
显示两个commit差异
差异都是用各个树来进行比较,然后通过比较程序,进行差异
五:远程版本库
重点解释了“本地分支”,“本地追踪分支”,“远程追踪分支”区别
远程分支几个易混淆的概念
远程版本库:为版本库提供友好的名字,里面的分支就时远程分支。
本地版本库:本地库
本地分支:本地分支(没有设置track)
本地追踪分支:设置了track远程分支的分支(一般也就我们本地开发的分支)
远程追踪分支:当fectch拉取远程分支时,实际下载的文件都在远程追踪个分支里。当执行pull时,这个分支与本地的分支(这个本地分支的upstream要是这个远程追踪分支)执行merge,用来追踪远程版本库中分支的变化。config文件里如下是记录本地各个分支HEAD的commit号与远程的各个分支Head的commit号。 建立这个refspec预示你要通过从原始版本库中抓取变更来持续更新本地版本库。下面就是这个映射关系
配置信息里的定义: remote.origin.fetch定义的是远程的别名, 以及与**本地追踪分支的关联**(refs/heads/\*), **远程追踪分支的关联**关系(refs/remotes/origin/*); remote.origin.fetch=+refs/heads/*:refs/remotes/origin/*git remote 命令创建,删除,操作和查看远程版本库。
引入的所有远程版本库都记录在.git/config文件中。可以通过一个本地库添加多个远程仓库。git remote add origin https://github.com/xxx(仓库地址) git remote update origin git remote show origin git remote rm origin git remote prune 删除”远程版本库已经删除的分支“的远程追踪分支建立本地分支与远程追踪分支的关联(即设立本地追踪分支)
[remote "origin"] url = git@gitee.com:rjb_555/BookerReading.git fetch = +refs/heads/*:refs/remotes/origin/* [branch "master"] remote = origin merge = refs/heads/master [branch "develop"] remote = origin merge = refs/heads/develop[remote "origin"] 定义是远程仓库地址,远程仓库别名,本地追踪分支(refs/heads/),远程追踪分支(refs/remotes/origin/)的关联关系;
git branch --track test origin/dev
或者
git checkout -b mypu --track origin/testbranchGit fetch,pull,push 的实质
git fetch (拉取远程版本库到远程追踪分支)
git pull (git fectch,git merge origin/master)
git push (变更发送到远程版本库,在同步到origin/master)指定远程版本库的指定分支进行推送
git push origin master
这里要理解git push本质"将变更打包“传输”在解包“放到指定的库中。所以git push 只是变更。所以可以将其推到指定的远程仓库。在非快进的push时,会遭到(non-fast forward)拒绝。 在此时因为远程的已经有人提交了。你的分支在当前远程分支之后,但有共同的提交记录。push -f 强制覆盖(覆盖掉别人的记录)。但此种情况一般都是先Pull,合并别人的提交。
删除与创建远程分支
git branch testbranch
git push origin testbranch(直接在远程创建了一根分支)
git push origin :foo原理(git push origin 源:目标)
git push origin testbranch (简写)(如果远程没偶testbranch ,会将本地的分支推送到远程的版本,即相当于在远程新建分支)
git push origin testbranch:testbranch
git push origin raotest:testbranch(将内容推到指定的分支)
Git push origin :testbranch (将空分支推发哦指定分支,即删除远程分支)
六:多个仓库可以共用一个对象库吗?(很重要,初学时的疑惑点)
经过实践是可以的。比如,当前库是A,在分支master上,我现在在当前目录添加一个远程的仓库B,幷Pull下来。这时pull下来的对象与库A共用一个对象库。所谓的共用一个对象仓库,就时存储真实数据的地方。当时一般情况我们不这么弄,因为如果都放入一个对象库里,会导致上库变大,上传时变慢。
当如果是这样一个使用场景(fork公司的参考到你自己的远程库,然后通过发pull request的工作方式):
公司的库A,你fork公式的库B,你在你本地添加了这两个的远程库,都pull下来,因为你们使用的是很多相同的文件,所以,不会造成很多重复的存储,因为文件都是按内容hash的。如果当远程同步不能工作时(将A的内容同步到B),可以先pull下A,然后本地合并到B,在通过将B库push 到你自己的远程,然后通过发push request方式请求公司的库的合并。当然你有权限合公司库,可以直接push到公司的库。
七:解释fast-forward,non-fast-forward
我们举例说明:
开发一直在master分支进行,但忽然有一个新的想法,于是新建了一个develop的分支,并在其上进行一系列提交,完成时,回到 master分支,此时,master分支在创建develop分支之后并未产生任何新的commit。此时的合并就叫fast forward。
反之,是non-fast-forwad
哈哈,在知道了,命令行,长长有fast-forward的日志信息!
八:解释git rebase ,git cherry-pick
者两命令,不常用,但有时能解决关键问题
git cherry-pick
git cherry-pick 通常用于将一个分支的特定提交引入一个不同的分支中。
举例说明
master分支已经有很多提交。master其中一个提交时修复一个bug时,这个bug在另一个分支也存在,需要将这个提交也放到dev分支。在dev会形成一个新的提交。
git checkout dev
git cherry-pick master~2
一句话总结,就时将一个分支的提交拷贝到另一个分支的最后面,幷形成一个新的提交(这句话很重要)
git rebase
rebase是个很重要的概念,需要比较综合的能力才能理解的比较好。我将在这篇文章里做详细的解释详解Git里的Rebase操作
九:提交范围(很重要)
很多命令都可以对提交范围执行某些操作。那么怎么表达这些提交范围呢?
"..."表示一个范围,“开始...结束"
"maser~2"表示master分支往后数第二个提交。(表示的是一个提交点)
示例
1. master~5 ... master~2,表示master的倒数第5个提交到倒数第2个提交之间的提交
2. topic...master,表示在master分支而不在topic分支生的提交
终于写完了这篇总结,以前看书《Git版本控制管理》JonLoeLiger 著 因为没有实践的前提,所以理解的不深。用了将近一年后,重新回过来看时,很做概念就很清晰了。
十:多人协作开发时,造成起点分叉的原因(还待研究)
iOS保持界面流畅的技巧(性能优化)
参考iOS 性能优化总结
参考微信读书 iOS 性能优化总结
参考iOS实时卡顿监控
参考移动端IM实践:iOS版微信界面卡顿监测方案
参考iOS保持界面流畅的技巧
本文是对上面几篇文章的总结。并与我自己的知识体系相融合,以达到一个自相融洽的整体。
卡顿原理
VSync信号到来时,系统图形服务会通过CADisplayLink等机制通知App,APP主线程开始在CPU中计算显示内容,比如视图的创建,布局计算,图片解码,文本绘制等。随后CPU会将计算好的内容提交到GPU,由GPU进行变换,合成,渲染。随后GPU会把渲染结果提交到帧缓冲区区,等待下一次VSync信号到来时显示到屏幕上。
由于垂直同步机制,若果在一个VSync时间内,CPU或者GPU没有完成内容的提交,则这个没有完成的提交不会显示到屏幕,在其提交后会到缓冲区,等待下一次机会在显示。那么这个下一次有可能是正常时间提交修改,则会将缓存区的内容覆盖。导致被覆盖的永远没机会显示了。就是掉帧了。
那么与runloop有什么关系呢?
Runloop的时间概念比1/60更小,也就是Runloop处理事物的时间远远比1/60要小。绝大部分时间是睡眠的。所以它们两个本身是没有关系的。绝大部分时候是主线程早就处理完毕所有显示数据,并提交到了渲染系统,渲染系统也完成了合成,也就是提交到了缓存区。只需要等待时钟的到来,将这个缓冲区的内容显示到屏幕上。
FPS的真正含义是,1s的时间真正有多少帧显示到了屏幕上。
卡顿监控思路
主线程卡顿监控
通过子线程监测主线程的runloop,判断两个状态区域之间的耗时是否达到一定阈值。这两个状态就是kCFRunLoopBeforeSources与kCFRunLoopAfterWaiting借助FPS监控
CADisplayLink 可以将其看做一个定时器。定时器都与机器的硬件有关系。而这个定时器是有屏幕“垂直时钟”驱动。也就是与垂直时钟同步,1/60时间跳动一次。因为CADisplayLink的回调也要在线程里执行,将其加入到主线程的Runloop里。runloop的TimerSource就会触发runloop的“叫醒”,执行该执行的内容。若果不将CADisplayLink加入,当然就不会定固定时间“叫醒”。
CADislayLink的timestampe的两次差为1s之内的tick次数,即使FPS。
线程卡顿监控方案一的实现
iOS实时卡顿检测
这一方案的思路,就是从引起卡顿的本质来优化。引起卡顿,在kCFRunLoopBeforeSources通知后执行主队列里的代码,执行block的代码等。或则在kCFRunLoopAfterWaiting被唤起后,也会执行队列里的代码,block代码。
#import <CrashReporter/CrashReporter.h>
@interface PerformanceMonitor ()
{
int timeoutCount;
CFRunLoopObserverRef observer;
@public
dispatch_semaphore_t semaphore;
CFRunLoopActivity activity;
}
@end
@implementation PerformanceMonitor
+ (instancetype)sharedInstance
{
static id instance = nil;
static dispatch_once_t onceToken;
dispatch_once(&onceToken, ^{
instance = [[self alloc] init];
});
return instance;
}
static void runLoopObserverCallBack(CFRunLoopObserverRef observer, CFRunLoopActivity activity, void *info)
{
PerformanceMonitor *moniotr = (__bridge PerformanceMonitor*)info;
moniotr->activity = activity;
dispatch_semaphore_t semaphore = moniotr->semaphore;
dispatch_semaphore_signal(semaphore);//没当状态发生变化的时候+1;这是在主线程执行
}
- (void)stop
{
if (!observer)
return;
CFRunLoopRemoveObserver(CFRunLoopGetMain(), observer, kCFRunLoopCommonModes);
CFRelease(observer);
observer = NULL;
}
- (void)start
{
if (observer)
return;
// 信号
semaphore = dispatch_semaphore_create(0);
// 注册RunLoop状态观察
CFRunLoopObserverContext context = {0,(__bridge void*)self,NULL,NULL};
observer = CFRunLoopObserverCreate(kCFAllocatorDefault,
kCFRunLoopAllActivities,
YES,
0,
&runLoopObserverCallBack,
&context);
CFRunLoopAddObserver(CFRunLoopGetMain(), observer, kCFRunLoopCommonModes);
//在子线程监控时长
//在子线程不断的监控信号量,如果在50 ms里还没有超时,也就是在50ms状态没有发生该边的话。就说明在两个状态的时间间隔里有执行时长超过50ms的
dispatch_async(dispatch_get_global_queue(0, 0), ^{
while (YES)
{
long st = dispatch_semaphore_wait(semaphore, dispatch_time(DISPATCH_TIME_NOW, 50*NSEC_PER_MSEC));
if (st != 0)
{
if (!observer)
{
timeoutCount = 0;
semaphore = 0;
activity = 0;
return;
}
//若果超时的是kCFRunLoopBeforeSources 或者kCFRunLoopAfterWaiting 就更能说明问题
//如果5此都是这样,说明有问题。几下主线程的调用堆栈。
if (activity==kCFRunLoopBeforeSources || activity==kCFRunLoopAfterWaiting)
{
if (++timeoutCount < 5)
continue;
PLCrashReporterConfig *config = [[PLCrashReporterConfig alloc] initWithSignalHandlerType:PLCrashReporterSignalHandlerTypeBSD
symbolicationStrategy:PLCrashReporterSymbolicationStrategyAll];
PLCrashReporter *crashReporter = [[PLCrashReporter alloc] initWithConfiguration:config];
NSData *data = [crashReporter generateLiveReport];
PLCrashReport *reporter = [[PLCrashReport alloc] initWithData:data error:NULL];
NSString *report = [PLCrashReportTextFormatter stringValueForCrashReport:reporter
withTextFormat:PLCrashReportTextFormatiOS];
NSLog(@"------------\n%@\n------------", report);
}
}
timeoutCount = 0;
}
});
}
@end
组件化系列(一) 组件化原理及方案
本系列文章是对大神的博客文章的研读与总结。我们公司从18年初开始组件化的开发的构建。为了理解组件开发的原理,找了相关资料做了对比分析。以下是我参考的文章
模块化与解耦
Casa的iOS应用架构谈 组件化方案。
蘑菇街的开源
Casa的组件化方案开源
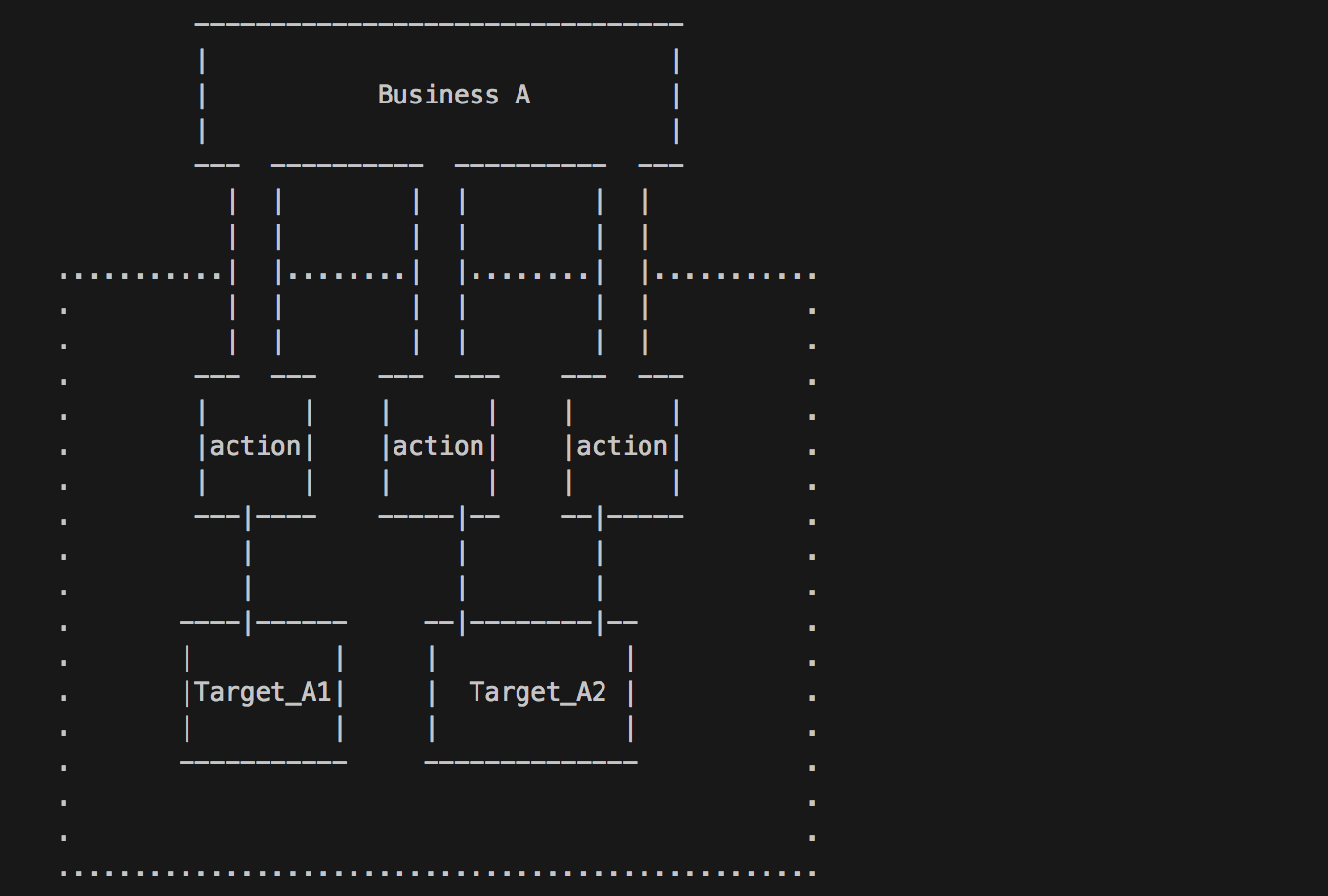
一:模块化与解耦
1.为什么模块化
因为在实际的开发中,项目业务较多,一个APP会有多个小组进行开发,比如我们公司的有数学组,语文组,英语组,商业组,等,出现的问题大多数情况下一个开发人员只关心我这个组的代码。这样在编译时实际上是编译整个项目,编译效率低。每个小组在同一个工程里增,删,改文件,xcode的工程文件会经常发生冲突(我们用git进行版本控制),合并代码时很痛苦。在整个项目查找自己忘记类名了的功能时,犹如大海捞针。有些基础模块核心模块需要专人维护,对基础的开发人员不开发,需要隔离基础库,也需要进行解耦。
这些理由已经足以说明进行模块化组件化的迫切了。
2. 模块设计原则
- 越底层的模块,应该越稳定,越抽象,越具有高度复用度。
- 不要让稳定的模块依赖不稳定的模块,减少依赖
- 提升模块的复用度,自完备性有时候要优于代码复用
- 每个模块只做好一件事情,不要让Common出现
- 按照你架构的层数从上到下依赖,不要出现下层模块依赖上层模块的现象,业务模块之间也尽量不要耦合
3. 模块解耦手段
要实现模块之间真正的解耦才算真正的模块化。
解耦目标:
在基于模块设计原则上让模块之间没有循环依赖,让业务模块之间解除依赖。
公共模块可以通过架构设计来避免耦合业务。但业务模块之间还是会有耦合的。
业务模块之间的比如页面跳转,数据传递,怎么实现解耦不同业务模块之间的代码调用呢?
1. 面向接口调用(很妙)
直接引用有依赖的情况
//A 模块
- (void)getSomeDataFromB {
B.getSomeData();
}
//B 模块
- (void)getSomeData {
return self.data;
}
//接口
@protocol BService<NSObject>
- (void)getSomeData;
@end
//A 模块,只依赖接口(针对协议编程)
- (void)getSomeDataFromB {
id b = findService(@protocol(BService));
b.getSomeData;
}
//B模块,实现BService接口
@interface B:NSObject<BService>
- (void)getSomeData {
return self.data;
}
这样就可以实现了既满足了模块之间的调用,也实现了解耦
优点
接口类似代码,可以非常灵活的定义函数和回调
缺点
1. 接口定义文件需要放在一个模块里以供依赖,但是这个模块不贡献代码。还好。
2. 使用麻烦,每个调用都需要定义一个service的接口,幷实现。
2. 面向自定义协议的调用
面向接口的调用的缺点导致幷不能满足所有的需求,也解耦的不彻底(对接口的依赖)。
终极手段就是通过定义一套自定义协议来实现模块间的通信,可以采用现成的协议如URL协议,简单,易于上手,这也是很多人采用url作为协议原因。可统一实现本地于远程的页面跳转,并且实现业务间的解耦。
要实现真正的解耦,采用注册机制。
3.利用运行时的反射机制
Object-C的反射机制是通过一个字符串找到一个类的类对象,即NSClassFromString();
要实现真正的解耦,可以采用通过反射机制获取类,在创建对象,实现跳转或者通信。这样就不用依赖”要跳转的类“了。
总结
以上的解耦方式是从模块化与解耦得到的启发。这些解耦方式无论是在平时开发中,还是要搭建组件化的框架都可以使用。具体的组件化框架我们将在下面对前人的组件化探索做下分析
二:模块拆分
基础库组件
第三方库如AFNetWorking,SDWebImage等,还有一些工具也要从主库重剥离出来,形成自己的私有基础仓库。服务组件
业务组件
https://blog.csdn.net/xinzhou201/article/details/51000807
- 拆分中遇到的问题 主工程与壳工程的pods版本的管理问题
三:蘑菇街组件化
蘑菇街的方案一
原理采用的是面向自定义协议的方式实现解耦。自定义协议采用的是现成的url协议,url协议成熟,方便,利用URL可以在这里做key值,方便的参数解析,与应用之间的调用相吻合。
嫌在这里看代码代码麻烦的话,可以下载我自己写的原理 Demo组件化原理分析
//Mediator3.h文件
typedef void(^componetBlock)(id param);
typedef id(^objectComponetBlock)(id param);
/*
原理就是将url与Block进行映射
url起到两个作用:一是作为key值与block进行映射,二是可以直接接参数就想普通url后面跟参数一样。
特别说明:
url传递参数受到一定的限制。比如对本地来说,需要传非常规的参数时,就办不到。
这里我自己的Demo直接将参数放在了函数后面省去对url进行解析的操作。实际的开发中将这个参数从url里解析出来。如果要传递非常规的参数。也可以直接在后面添加有一个param。
*/
@interface Mediator3 : NSObject
+ (instancetype)shareInstance;
//指定相应的url的执行操作
//例如,只是简单的打开一个页面
- (void)registerURLPattern:(NSString *)urlPattern toHandler:(componetBlock)block;
//打开某个页面
- (void)openURL:(NSString *)url withParam:(id)param;
//指定相应rul的执行操作,并给一个返回值
//例如打开一个页面,或者在一个组件里面取值后返回来
- (void)registerURLPattern:(NSString *)urlPattern toObjectHandler:(objectComponetBlock)block;
//取得某个组件操作后的值
- (id)objectForURL:(NSString *)url withParam:(id)param;
//Mediator3.m文件
@interface Mediator3()
@property (nonatomic, strong)NSMutableDictionary *cache;
@end
@implementation Mediator3
- (instancetype)init {
if(self = [super init]){
_cache = [[NSMutableDictionary alloc]init];
}
return self;
}
+ (instancetype)shareInstance {
static dispatch_once_t onceToken;
static Mediator3 *mediator = nil;
dispatch_once(&onceToken, ^{
mediator = [[self alloc]init];
});
return mediator;
}
- (void)registerURLPattern:(NSString *)urlPattern toHandler:(componetBlock)block {
[self.cache setObject:block forKey:urlPattern];
}
- (void)openURL:(NSString *)url withParam:(id)param {
componetBlock block = [self.cache objectForKey:url];
if(block){
block(param);
}
}
- (void)registerURLPattern:(NSString *)urlPattern toObjectHandler:(objectComponetBlock)block {
[self.cache setObject:block forKey:urlPattern];
}
- (id)objectForURL:(NSString *)url withParam:(id)param{
objectComponetBlock block = [self.cache objectForKey:url];
if(block){
return block(param);
}
return nil;
}
@end
//BookDetailViewController.m
@implementation BookDetailViewController
+ (void)load {
//实现跳转功能
[[Mediator3 shareInstance] registerURLPattern:@"weread://bookDetail" toHandler:^(id param) {
NSDictionary *paramDict = (NSDictionary *)param;
BookDetailViewController *bookDetailVC = [[BookDetailViewController alloc]initWithBookId:paramDict[@"bookId"]];
UINavigationController *nav = (UINavigationController *) [UIApplication sharedApplication].keyWindow.rootViewController;
[nav pushViewController:bookDetailVC animated:YES];
}];
//只是取值的操作
[[Mediator3 shareInstance]registerURLPattern:@"weread://bookCount" toObjectHandler:^id(id param) {
//执行一定的操作后
return @"5";
}];
//ReadingViewController.m
- (void)viewDidLoad {
[super viewDidLoad];
//注册url与block的映射,实现调转的操作
[[Mediator3 shareInstance] openURL:@"weread://bookDetail" withParam:@{@"bookId":@"2"}];
//注册url与block映射,实现只是取值的操作
NSString *bookCount = [[Mediator3 shareInstance] objectForURL:@"weread://bookCount" withParam:@""];
NSLog(@"这是从某个组件取回来的值%@",bookCount);
}
蘑菇街的方案二
实现原理:
面向接口调用,即新开了一个对象叫做ModuleManager,提供了一个registerClass:forProtocol:的方法,注册后,@protocol和Class进行配对。因此ModuleManager中就有了一个字典来记录这个配对。
当有涉及非常规参数的调用时,业务方就不会去使用[MGJRouter openURL:@"mgj://detail?id=404"]的方案了,转而采用ModuleManager的classForProtocol:方法。业务传入一个@protocol给ModuleManager,然后ModuleManager通过之前注册过的字典查找到对应的Class返回给业务方,然后业务方再自己执行alloc和init方法得到一个符合刚才传入@protocol的对象,然后再执行相应的逻辑。
这里的protocol统样起到两个作用,一是key值,另一个是起到定义调用接口的作用,可以定义任意类型的参数。
缺点
1. 被调用方与调用方,虽然不相互依赖,但都得依赖这个协议。这实际上是一种不彻底的解耦。
- 同url注册形式一样,都得维持注册表。
四:casa组件化
基于Mediator模式和Target-Action模式,中间采用了runtime来完成调用。这套组件化方案将远程应用调用和本地应用调用做了拆分,而且是由本地应用调用为远程应用调用提供服务
实现原理
[[CTMediator sharedInstance] performTarget:targetName action:actionName params:@{...}]向CTMediator发起跨组件调用,CTMediator根据获得的target和action信息,通过objective-C的runtime转化生成target实例以及对应的action选择子,然后最终调用到目标业务提供的逻辑,完成需求。
下面是工程实践
下面是casa开源的实现的头文件。.m文件请自行下载
//casa开源的CTMeditor.h
@interface CTMediator : NSObject
+ (instancetype)sharedInstance;
// 远程App调用入口
- (id)performActionWithUrl:(NSURL *)url completion:(void(^)(NSDictionary *info))completion;
// 本地组件调用入口
- (id)performTarget:(NSString *)targetName action:(NSString *)actionName params:(NSDictionary *)params shouldCacheTarget:(BOOL)shouldCacheTarget;
- (void)releaseCachedTargetWithTargetName:(NSString *)targetName;
@end
//CTMeditor.m
略
采用运行时构建可执行的NSInvocation。在内部都给其添加了前缀
NSString * targetClassString = [NSString stringWithFormat:@"Target_%@", targetName];
NSString *actionString = [NSString stringWithFormat:@"Action_%@:", actionName];
//Target_B.h
@interface Target_B : NSObject
- (UIViewController *)Action_DemoModuleBDetailViewController:(NSDictionary *)dict;
@end
//Target_B.m
#import "Target_B.h"
#import "DemoModuleBDetailViewController.h"
@implementation Target_B
- (UIViewController *)Action_DemoModuleBDetailViewController:(NSDictionary *)param {
DemoModuleBDetailViewController *bDetailVC = [[DemoModuleBDetailViewController alloc]init];
return bDetailVC;
}
@end
//ViewController.m
//这是调用方
#import "CTMediator+CTMediatorModuleAActions.h"
#import "CTMediator+CTMediatorModuleBActions.h"
- (void)viewDidLoad {
//直接调用
if (indexPath.row == 6) {
[[CTMediator sharedInstance] performTarget:@"InvalidTarget" action:@"InvalidAction" params:nil shouldCacheTarget:NO];
}
//通过分类调用
if(indexPath.row == 7){
UIViewController *vc = [[CTMediator sharedInstance]CTMediator_viewControllerForModuleBDetail:@{}];
[self.navigationController pushViewController:vc animated:YES];
}
}
从.h文件里可以看到,外部的调用将远程与本地分开,内部实现时远程利用了本地(通过解析url,将url转换成了本地的调用)。
Mediator分别对每一个模块有个一个分类,提供对外部的调用的列表。这些分类被需要调用的模块所依赖。也就是只需要依赖Mediator就可以了,是单向依赖。
为了更好的实现组件对外接口的管理。此种方案专门针对每个模块有一个Target_A类似的对外服务接口的实现。
用户调用都是通过对Mediator的分类,对固定的模块的类的名字的反射,来对Target_A的调用,当然就调用到了A的服务。
此种方式为了使代码方便管理,会为每个模块提供Target和一个对Mediator的分类。
Mediator与其分类可以是单独一个repo,方便其他组件依赖。也就是其他组件只依赖于这个中间件。解耦与组件化就完成了。
五:总结
组件化就是在与解耦,解耦的方式大致就是上面提到的三种方法(也可能有其他办法,但至少现在我看到的最好实践就这三)。然后是基于各个原理的工程化实践。从工程实践来看casa的Mediator+target-action更胜一筹。思路清晰,调用统一,没有注册机制的维护,模块的服务的实现(Target)在同一个地方,不用耦合到真正的模块里。
多说一句,滴滴组件化,页面间的跳转采用openURL,页面在+(void)load方法里进行注册,ONERoute内部保存一份URL与Class的对应表。当调用openURL时,会查找到相应的类,然后生成相应的实例对象。
最后强烈建议大家认真读Casa的iOS应用架构谈 组件化方案。
Copyright © 2015 Powered by MWeb, Theme used GitHub CSS.